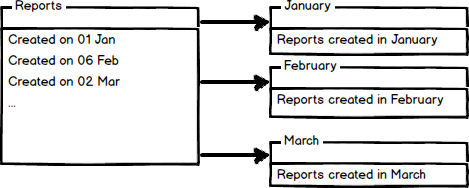
Horizontal Partitioning a table using Queries
Horizontal partitioning divides a table into multiple tables that
contain the same number of columns, but fewer rows. For example, if a
table contains a large number of rows that represent monthly reports it
could be partitioned horizontally into tables by years, with each table
representing all monthly reports for a specific year. This way queries
requiring data for a specific year will only reference the appropriate
table. Tables should be partitioned in a way that queries reference as
few tables as possible.
 Tables are horizontally partitioned based on a column which will be
used for partitioning and the ranges associated to each partition.
Partitioning column is usually a datetime column but all data types that
are valid for use as index columns can be used as a partitioning
column, except a timestamp column. The ntext, text, image, xml,
varchar(max), nvarchar(max), or varbinary(max), Microsoft .NET Framework
common language runtime (CLR) user-defined type, and alias data type
columns cannot be specified.
There are two different approaches we could use to accomplish table
partitioning. The first is to create a new partitioned table and then
simply copy the data from your existing table into the new table and do a
table rename. The second approach is to partition an existing table by
rebuilding or creating a clustered index on the table.
Tables are horizontally partitioned based on a column which will be
used for partitioning and the ranges associated to each partition.
Partitioning column is usually a datetime column but all data types that
are valid for use as index columns can be used as a partitioning
column, except a timestamp column. The ntext, text, image, xml,
varchar(max), nvarchar(max), or varbinary(max), Microsoft .NET Framework
common language runtime (CLR) user-defined type, and alias data type
columns cannot be specified.
There are two different approaches we could use to accomplish table
partitioning. The first is to create a new partitioned table and then
simply copy the data from your existing table into the new table and do a
table rename. The second approach is to partition an existing table by
rebuilding or creating a clustered index on the table.
An example of horizontal partitioning with creating a new partitioned table
SQL Server 2005 introduced a built-in partitioning feature to
horizontally partition a table with up to 1000 partitions in SQL Server
2008, and 15000 partitions in SQL Server 2012, and the data placement is
handled automatically by SQL Server. This feature is available only in
the Enterprise Edition of SQL Server.
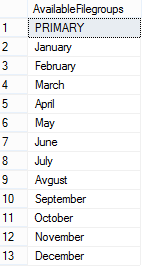
To create a partitioned table for storing monthly reports we will
first create additional filegroups. A filegroup is a logical storage
unit. Every database has a primary filegroup that contains the primary
data file (.mdf). An additional, user-defined, filegrups can be created
to contain secondary files (.ndf). We will create 12 filegroups for
every month:
 To check created and available file groups in the current database run the following query:
To check created and available file groups in the current database run the following query:
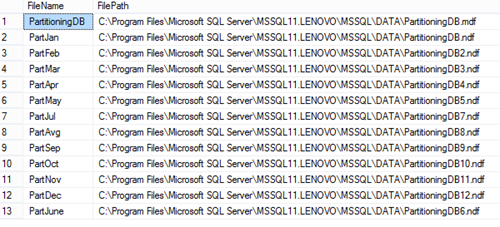
 When filegrups are created we will add .ndf file to every filegroup:
When filegrups are created we will add .ndf file to every filegroup:
 The same way files to all created filegroups with specifying the
logical name of the file and the operating system (physical) file name
for each filegroup e.g.:
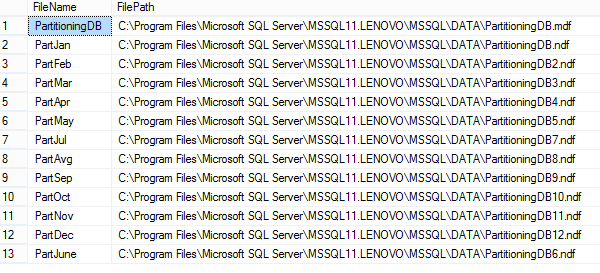
To check files created added to the filegroups run the following query:
The same way files to all created filegroups with specifying the
logical name of the file and the operating system (physical) file name
for each filegroup e.g.:
To check files created added to the filegroups run the following query:

 After creating additional filegroups for storing data we’ll create a
partition function. A partition function is a function that maps the
rows of a partitioned table into partitions based on the values of a
partitioning column. In this example we will create a partitioning
function that partitions a table into 12 partitions, one for each month
of a year’s worth of values in a datetime column:
To map the partitions of a partitioned table to filegroups and
determine the number and domain of the partitions of a partitioned table
we will create a partition scheme:
After creating additional filegroups for storing data we’ll create a
partition function. A partition function is a function that maps the
rows of a partitioned table into partitions based on the values of a
partitioning column. In this example we will create a partitioning
function that partitions a table into 12 partitions, one for each month
of a year’s worth of values in a datetime column:
To map the partitions of a partitioned table to filegroups and
determine the number and domain of the partitions of a partitioned table
we will create a partition scheme:
 Now we’re going to create the table using the PartitionBymonth partition scheme, and fill it with the test data:
Now we’re going to create the table using the PartitionBymonth partition scheme, and fill it with the test data:
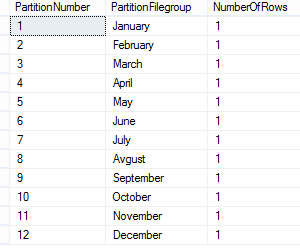
 We will now verify the rows in the different partitions:
We will now verify the rows in the different partitions:
 Now just copy data from your table and rename a partitioned table.
Now just copy data from your table and rename a partitioned table.



No comments:
Post a Comment