SQL 2016 has a number of major enhancements which will help whether or not you are implementing on-prem, in Azure or in a hybrid model.
Microsoft released the preview of SQL Server 2016 (versioned as Consumer Technology Preview (CTP) 2.0). In a slight contrast to other recent releases of SQL Server, 2016 is not as directly focused on Azure features mainly because Microsoft is moving towards a common code base for both the on-premises version of SQL Server and Azure SQL Database which will allow for changes to come into the product in more of an Agile fashion.
For example, row-level security (RLS) and Dynamic Data Masking have both been in preview in Azure SQL DB for several months now and are included in this CTP. So effectively, Azure SQL DB gets the new toys first where they get tested out, and then the on-premises products benefit by getting features more quickly (in service packs or cumulative updates). This rapid development cycle is great for development shops who are requesting the new features -- but where does it leave large enterprises who have to deal with testing cycles and regulation to upgrade versions? Don't worry, Microsoft has a feature to meet your needs as well.
Query Store
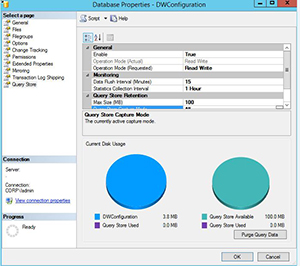
One common problem many organizations face when upgrading versions of SQL Server is changes in the query optimizer (which happen from version to version) negatively impacting performance. Without comprehensive testing, this has traditionally been a hard problem to identify and then resolve. The Query Store feature maintains a history of query execution plans with their performance data, and quickly identifies queries that have gotten slower recently, allowing administrators or developers to force the use of an older, better plan if needed. The Query Store is configured at the individual database level.
One common problem many organizations face when upgrading versions of SQL Server is changes in the query optimizer (which happen from version to version) negatively impacting performance. Without comprehensive testing, this has traditionally been a hard problem to identify and then resolve. The Query Store feature maintains a history of query execution plans with their performance data, and quickly identifies queries that have gotten slower recently, allowing administrators or developers to force the use of an older, better plan if needed. The Query Store is configured at the individual database level.
Polybase
Hadoop and Big Data have been all the rage in the last several years. I think some of that was industry hype, but Hadoop is a scalable, cost-effective way to store large amounts of data. Microsoft had introduced Polybase, a SQL Server connector to Hadoop (and Azure Blob Storage) to its data warehouse appliance Analytics Platform System in 2015. But now Microsoft has incorporated that functionality into the regular on-premises product. This feature will benefit you if your regular data processing involves dealing with a lot of large text files -- they can be stored in Azure Blob Storage or Hadoop, and queried as if they were database tables. A common scenario where you might use this would be an extract, transform and load (ETL) process, where you were taking a subset of the text file to load into your database.
Hadoop and Big Data have been all the rage in the last several years. I think some of that was industry hype, but Hadoop is a scalable, cost-effective way to store large amounts of data. Microsoft had introduced Polybase, a SQL Server connector to Hadoop (and Azure Blob Storage) to its data warehouse appliance Analytics Platform System in 2015. But now Microsoft has incorporated that functionality into the regular on-premises product. This feature will benefit you if your regular data processing involves dealing with a lot of large text files -- they can be stored in Azure Blob Storage or Hadoop, and queried as if they were database tables. A common scenario where you might use this would be an extract, transform and load (ETL) process, where you were taking a subset of the text file to load into your database.
Stretch Database
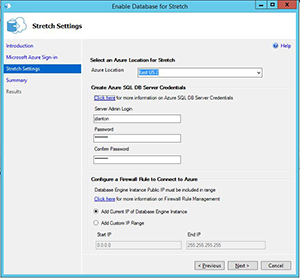
One common idiom in recent years, is how cheap storage is. While it may be cheap to buy a 3TB drive from Amazon, if you are buying enterprise-class SAN storage or enterprise SSDs, you will know that storage is still very expensive. Microsoft is trying to help reduce your storage (and processing costs) with a hybrid feature called "Stretch Database." The basics of Stretch Database are that some part of your tables (configurable or automated) will be moved into an Azure SQL Database in the cloud in a secure fashion. When you query those tables, the query optimizer knows which rows are on your server and which rows are in Azure, and divides the workload accordingly. The query processing on the Azure rows takes place in Azure so the only latency is for the return of the rows over the network. As an additional enhancement, you are only charged for the SQL Database in Azure when it is used for queries. You do, however, pay for the Azure Blob storage, which, generally speaking, is much cheaper than enterprise storage.
One common idiom in recent years, is how cheap storage is. While it may be cheap to buy a 3TB drive from Amazon, if you are buying enterprise-class SAN storage or enterprise SSDs, you will know that storage is still very expensive. Microsoft is trying to help reduce your storage (and processing costs) with a hybrid feature called "Stretch Database." The basics of Stretch Database are that some part of your tables (configurable or automated) will be moved into an Azure SQL Database in the cloud in a secure fashion. When you query those tables, the query optimizer knows which rows are on your server and which rows are in Azure, and divides the workload accordingly. The query processing on the Azure rows takes place in Azure so the only latency is for the return of the rows over the network. As an additional enhancement, you are only charged for the SQL Database in Azure when it is used for queries. You do, however, pay for the Azure Blob storage, which, generally speaking, is much cheaper than enterprise storage.
JSON Support
In addition to supporting direct querying to Hadoop, SQL Server 2016 adds support for the lingua franca of Web applications: Java Script Object Notation (JSON). Several other large databases have added this support in recent years as the trend towards Web APIs using JSON has increased. The way this is implemented in SQL 2016 is very similar to the way XML support is built in with FOR JSON and OPENJSON -- providing the ability to quickly move JSON data into tables.
In addition to supporting direct querying to Hadoop, SQL Server 2016 adds support for the lingua franca of Web applications: Java Script Object Notation (JSON). Several other large databases have added this support in recent years as the trend towards Web APIs using JSON has increased. The way this is implemented in SQL 2016 is very similar to the way XML support is built in with FOR JSON and OPENJSON -- providing the ability to quickly move JSON data into tables.
Row Level Security
A feature that other databases have had for many years, and SQL Server has lacked natively is the ability to provide row-level security (RLS). This restricts which users can view what data in a table, based on a function. SQL Server 2016 introduces this feature, which is very useful in multi-tenant environments where you may want to limit data access based on customer ID. I've seen some customized implementations of RLS at clients in the past, and they weren't pretty. It is hard to execute at scale. The implementation of RLS in SQL 2016 still has it limits (updates and inserts are not covered), but it is good start on a much-needed feature.
A feature that other databases have had for many years, and SQL Server has lacked natively is the ability to provide row-level security (RLS). This restricts which users can view what data in a table, based on a function. SQL Server 2016 introduces this feature, which is very useful in multi-tenant environments where you may want to limit data access based on customer ID. I've seen some customized implementations of RLS at clients in the past, and they weren't pretty. It is hard to execute at scale. The implementation of RLS in SQL 2016 still has it limits (updates and inserts are not covered), but it is good start on a much-needed feature.
Always Encrypted
It seems like every month, we hear about some company having a major data breach. Encryption works, but many companies do not or cannot implement it all the way through the stack, leaving some layer data available for the taking as plain text. SQL Server has long supported both column-level encryption, encryption at rest, and encryption in transit. However these all had to be configured independently and were frequently misconfigured. Always Encrypted is new functionality through the use of an enhanced client library at the application so the data stays encrypted in transit, at rest and while it is alive in the database. Also given Microsoft's push towards the use of Azure, easy encryption makes for a much better security story.
It seems like every month, we hear about some company having a major data breach. Encryption works, but many companies do not or cannot implement it all the way through the stack, leaving some layer data available for the taking as plain text. SQL Server has long supported both column-level encryption, encryption at rest, and encryption in transit. However these all had to be configured independently and were frequently misconfigured. Always Encrypted is new functionality through the use of an enhanced client library at the application so the data stays encrypted in transit, at rest and while it is alive in the database. Also given Microsoft's push towards the use of Azure, easy encryption makes for a much better security story.
In-Memory Enhancements
SQL Server 2014 introduced the concept of in-memory tables. These were optimally designed for high-speed loading of data with no locking issues or high-volume session state issues. While this feature sounded great on paper, there were a lot of limitations particularly around constraints and procedures. In SQL Server 2016, this feature is vastly improved, supporting foreign keys, check and unique constraints and parallelism. Additionally, tables up to 2TB are now supported (up from 256GB). Another part of in-memory is column store indexes, which are commonly used in data warehouse workloads. This feature was introduced in SQL 2012 and has been enhanced in each version since. In 2016 it receives some enhancements around sorting and better support with AlwaysOn Availability Groups.
SQL Server 2014 introduced the concept of in-memory tables. These were optimally designed for high-speed loading of data with no locking issues or high-volume session state issues. While this feature sounded great on paper, there were a lot of limitations particularly around constraints and procedures. In SQL Server 2016, this feature is vastly improved, supporting foreign keys, check and unique constraints and parallelism. Additionally, tables up to 2TB are now supported (up from 256GB). Another part of in-memory is column store indexes, which are commonly used in data warehouse workloads. This feature was introduced in SQL 2012 and has been enhanced in each version since. In 2016 it receives some enhancements around sorting and better support with AlwaysOn Availability Groups.
No comments:
Post a Comment