ProblemAn auditor has taken a look at our SQL Servers and has told us that we need to audit login failures to the SQL Servers themselves. How do we do this?
SolutionSQL Server permits the auditing of both login successes and failures, depending on your need. The way to turn this auditing on is by using SQL Server Management Studio. Connect to the SQL Server in Object Explorer and then right-click on the SQL Server and choose the Properties option from the pop-up menu. You should see the server properties like so:
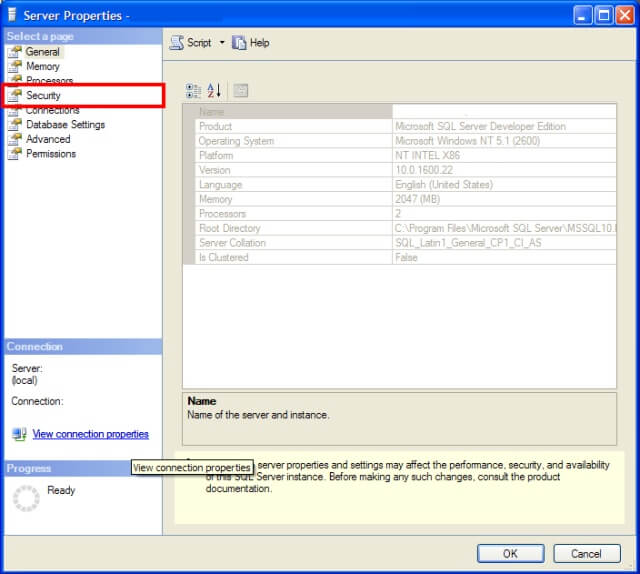
You'll want to click on the Security page (highlighted in the previous image) which will bring you to where you can set the login auditing:
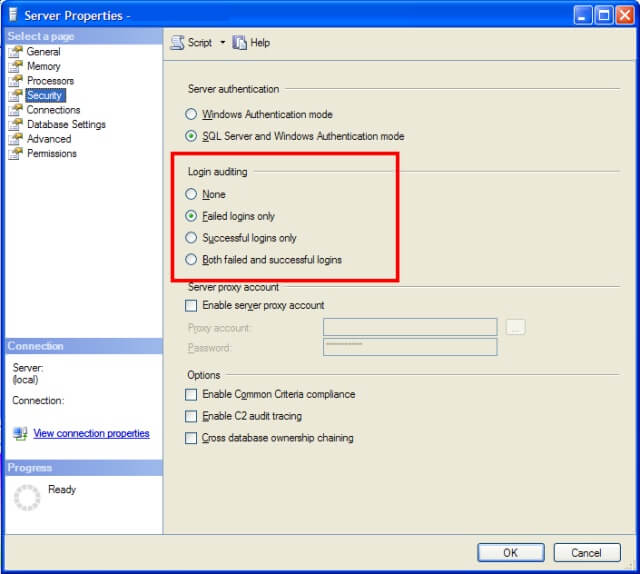
There are four options available:
- None - Neither successful nor failed logins will be audited.
- Failed logins only - Failed logins will be audited, but successful logins will be ignored.
- Successful logins only - Successful logins will be audited, but failed logins will be ignored.
- Both failed and successful logins - Login will be audited regardless of success and failure.
When you've made your choice, click the OK button. The setting for login auditing is actually a registry entry which differs based on SQL Server version and SQL Server instance name. SQL Server only reads this setting when the SQL Server service starts up. Therefore, for this setting to take effect, you'll need to restart the SQL Server service. Because it is a registry setting, the only easy way to set how to audit is through the GUI. There isn't a way using T-SQL without using one of the extended stored procedures that hits the registry directly.
A word about the various settings. At the very least, you should be auditing failed logins on production systems. There may be cases where it is necessary to audit successful logins, but realize that auditing successful logins will likely generate a lot of events to sift through. On extremely sensitive systems it is important to have this level of control. However, on less critical systems, you may be better served to only audit failed logins so you don't get overwhelmed with the number of events. If you have a log management solution, by all means audit both.
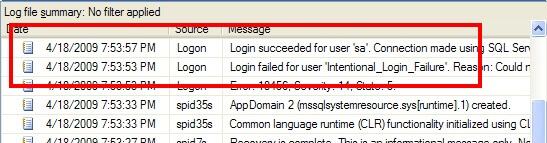
Once you've turned on auditing, the next step is to be able to find the results of said auditing. The first place where the audit information is recorded is the SQL Server log. For instance, an audit success by the "sa" account and an audit failure are shown in the following excerpt:
If you want to view the contents of the SQL Server log by using T-SQL, there's an undocumented (but well known) extended stored procedure called xp_readerrorlog. You can use it to dump the results of the error log to a recordset by:
EXEC xp_readerrorlog;
To read further back, you can give this extended stored procedure an integer parameter which corresponds to the order of the SQL Server log. 0 represents the current log, with each number after that referring to the next one back. So to see the contents of the 3rd log (including the current one) you would pass a parameter of 2 (counting up from 0 - 0, 1, 2 would be the third), you would execute:
EXEC xp_readerrorlog 2;EXEC sp_readerrorlog 0, 1, 'Login failed'
If you have log management software, another good place to look is the Application event log for the operating system. You can view this by using the Computer Management tool. If you expand System Tools and then Event Viewer, you'll see the Application event log like so:
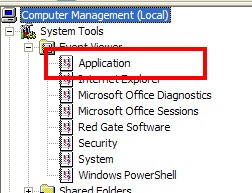
If you look in this event log, you'll be looking for events with a source of MSSQLSERVER or MSSQL$<Instance Name>. For instance, the following shows the audit success and failure events we looked at before in the SQL Server log:

Successful logins for SQL Server 2005 and 2008 will have an event ID of 18454 and failed logins will have an event ID of 18456. SQL Server 2000 uses the same event ID for both, making it impossible to determine of the event signifies a success or failure without looking at the event details. As a result, I would recommend only auditing failures to eliminate the confusion. Once you have determined the correct events, you can look at the event log details to see what login was attempted. For instance, here is the failed login attempt:
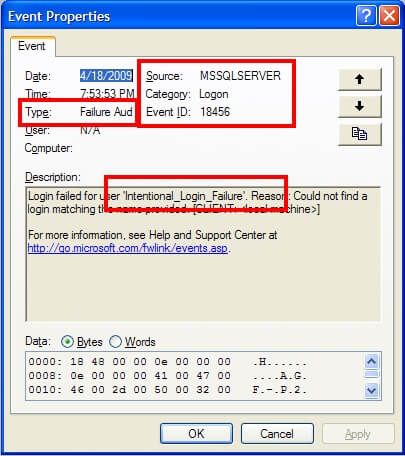
and here is the successful login attempt:
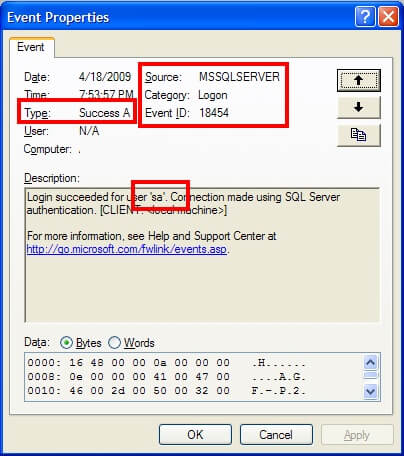
The details of what account was attempted is stored within the description of the event log. Therefore, if you need to automate the retrieval of audit successes or failures, make sure the application can retrieve the details and parse the text accordingly.
